- Published on
Elasticsearch 向量搜索与 NLP 模型集成实践指南
- Authors

- Name
- Liant
Elasticsearch 向量搜索
演示Elasticsearch向量搜索,通过文字搜索图片,相识图片,情感,实体,语义搜索。
什么是向量搜索
含义
向量搜索可利用 Machine Learning (ML) 来捕获非结构化数据(包括文本和图像)的含义和上下文,并将其转换为数字化表示形式。向量搜索常用于语义搜索,通过利用相似最近邻 (ANN) 算法来找到相似数据。与传统的关键字搜索相比,向量搜索产生的结果相关度更高,执行速度也更快。

如下就是一个向量值,做向量化数据可以是文字,图片,音频,视频等。取决于模型的能力。
- 不同模型,维度数量不一样。384,512等等的都比较常见
- 有多少个维度,就有多少个浮点值
[ -0.24778835475444794, 0.1283694952726364, 0.265764057636261, 0.10335895419120789, -0.011643894016742706, 0.0073570311069488525, -0.28859424591064453, ... -0.24171176552772522 ]
向量搜索引擎的工作原理?
向量搜索引擎也称为向量数据库、语义搜索或余弦搜索,可用于查找给定(向量化)查询的最近邻。
传统搜索方法依赖于关键字的提及率、词汇相似度和单词出现的频率,而向量搜索引擎则是使用嵌入空间中的距离信息来表示相似度。这样一来,查找相关数据就变成了搜索您查询内容的最近邻。
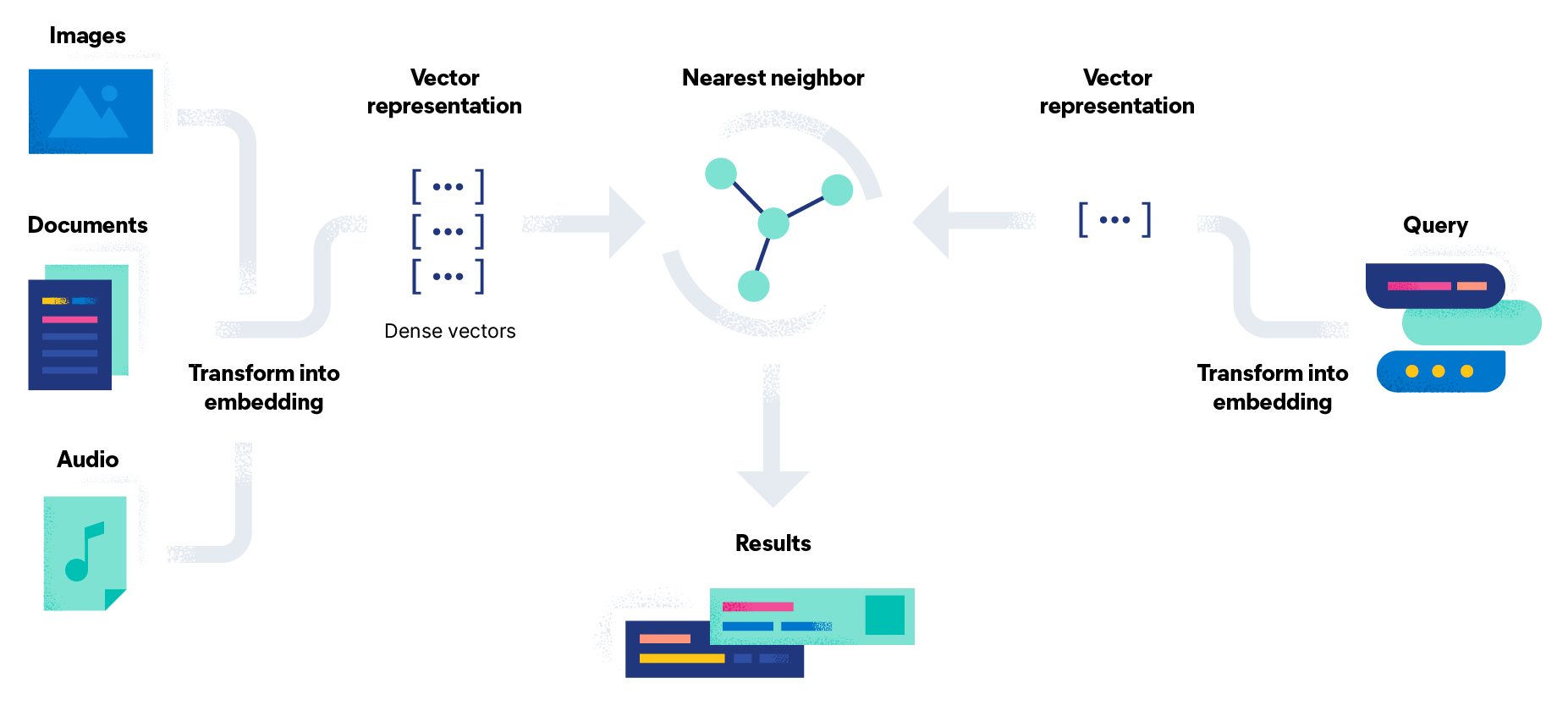
向量嵌入
向量嵌入是数据和相关上下文的数字化表示,存储在高维度(密集)向量中。用于生成嵌入的模型可以使用数百万的示例进行训练后得到,可提供更相关也更准确的结果。在某些用例中,您收集或精心设计的为呈现文档关键特性的数值数据,可以作为嵌入来使用。您只需能够高效地进行搜索即可。
相似度分数
向量搜索引擎的核心思想是,如果数据和文档相似,它们的向量也会相似。使用向量嵌入对查询和文档都完成索引后,您就可找到与您的查询最近邻相似的文档。
人工神经网络 (ANN) 算法
传统的最近邻算法(如 k 最近邻算法 (kNN))会导致执行时间过长并占用计算资源。ANN 牺牲了完美准确性,以换取在高维度嵌入空间中实现大规模高效运行。
应用方向
以文搜图
使用AI模型对文字进行向量处理,生成密集向量,通过利用相似最近邻 (ANN) 算法来找到相似数据,查找相关图片。
以图搜图
使用AI模型对输入图片进行向量处理,生成密集向量,通过利用相似最近邻 (ANN) 算法来找到相似数据,查找相似图片。
语义搜索
向量搜索支持语义搜索或相似度搜索。由于可在嵌入中捕获数据的含义和上下文,向量搜索因而能够理解用户的意思,而无需做到关键字完全匹配。它可以处理文本型数据(文档)、图像和音频。您可以轻松快速地找到与所查询内容相似或相关的产品。
问题回答
在将文档转换为文本嵌入时,可以与现代自然语言处理 (NLP) 相结合,从而提供问题的全文本答案。使用这种方法,用户无需学习冗长的手册,而且您的团队也能够更快地提供答案。
“问答”转换器模型可以采用文档知识库和您的当前问题的文本嵌入表示形式,以提供最接近的匹配项作为“答案”。
资料
应用演示
以一个项目为例,演示常见的场景.
该项目演示功能:
Image Search (以文搜图)Sentiment Analysis (情感分析)NER (实体识别)Fill Mask (完形填空)Text Search (上下文搜索)Similar Image (以图搜图)Question Answer (问答)
注意
使用模型导入需要白金版授权
# 获取授权,试用一个月 curl -XPOST http://es01:9200/_license/start_trial?acknowledge=true爬梯子最省心
使用Docker演示省心
项目中需要完整演示需要内存为21GB,也可以只导入部分模型演示
使用eland向集群导入大模型时,在window系统中不能直接别识别成命令执行,需要如下使用
python D:\workspace-other\flask-elastic-nlp\.venv\Scripts\eland_import_hub_model --url http://es1:9200 --hub-model-id dslim/bert-base-NER --task-type ner --start在Windows系统下激活python的虚拟环境
\.venv\Scripts\activate
模型接口 模型部署文档API
临时Elasticsearch服务地址: http://db-base-es-v8.dev.com:9200/
为导入模型的id: sentence-transformers__clip-vit-b-32-multilingual-v1 (文字模型)
# 查询模型状态
GET _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/_stats
# 停止模型部署
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_stop
# 启用模型
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_start
不使用Elasticsearch的向量
自己调用模型生成向量,不使用Elasticsearch的内置模型功能
以文搜图
flask-elastic-nlp 中搜图使用的模型为 clip-ViT-B-32 (该模型支持中文)
如果使用Elasticsearch的模型功能,步骤为:
导入模型并启动
eland_import_hub_model --url https://elastic:changeme@127.0.0.1:9200 --hub-model-id sentence-transformers/clip-ViT-B-32-multilingual-v1 --task-type text_embedding --start --ca-certs app/conf/ca.crt新建pipeline,指定模型,写入数据时指定pipeline(目前只支持text直接使用pipeline)
// 创建预处理 text_embedding PUT _ingest/pipeline/text_embedding { "processors": [ { "inference": { "model_id": "sentence-transformers__clip-vit-b-32-multilingual-v1", "target_field": "text_embedding", "field_map": { "content": "text_field" } } } ] } // 写入数据 text_embedding POST les-miserable-embedded/_doc/1001?pipeline=text_embedding { "content": "Ashutosh Kulkarni is CEO of Elastic NV." }应用程序请求ES服务器调用模型接口,ES服务把向量化输入值并返回给应用程序. infer-trained-model文档
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer { "docs":[ { "text_field": "question answering context" } ] }应用程序把得到的向量化值以knn的搜索方式请求ES服务查询数据
{ "knn": { "field": "image_embedding", "query_vector": [ # 512维 ... ], "k": 5, "num_candidates": 100 }, "fields": [ "photo_description", "ai_description", "photo_url", "photo_image_url", "photographer_first_name", "photographer_username", "photographer_last_name", "photo_id" ] }
演示代码只是例子,并不能直接使用
修改后变更为:
- 应用程序启动时加载模型
- 插入数据使用模型向量化数据
- 应用程序先向量化输入值,在把向量值请求ES搜索
需要在写入数据的时候启用一个向量化服务,搜索的时候在程序段向量化数据
- 图片mapping
{
"image-embeddings": {
"mappings": {
"properties": {
"ai_description": {
"type": "text"
},
"exif_camera_make": {
"type": "keyword"
},
"exif_camera_model": {
"type": "keyword"
},
"exif_iso": {
"type": "integer"
},
"image_embedding": {
"type": "dense_vector",
"dims": 512,
"index": true,
"similarity": "cosine"
},
"photo_description": {
"type": "text"
},
"photo_id": {
"type": "keyword"
},
"photo_image_url": {
"type": "keyword"
},
"photo_url": {
"type": "keyword"
},
"photographer_first_name": {
"type": "keyword"
},
"photographer_last_name": {
"type": "keyword"
},
"photographer_username": {
"type": "keyword"
}
}
}
}
}
- 项目中代码改动
# 向量化图片,并写入到es中
@app.route('/upload_search', methods=['GET', 'POST'])
def upload_search():
index_name = INDEX_IM_EMBED
if not es.indices.exists(index=index_name):
return render_template('similar_image1.html', title='图片上传', index_name=index_name, missing_index=True)
form = InputFileForm()
if request.method == 'GET':
return render_template('similar_image1.html', title='图片上传', form=form, model_up=True)
if not form.validate_on_submit():
return redirect(url_for('similar_image1'))
if request.files['file'].filename == '':
return render_template('similar_image1.html', title='图片上传', form=form,
err='No file selected', model_up=True)
# 保存图片
filename = secure_filename(form.file.data.filename)
url_dir = 'static/tmp-uploads/'
upload_dir = 'app/' + url_dir
upload_dir_exists = os.path.exists(upload_dir)
if not upload_dir_exists:
os.makedirs(upload_dir)
file_path = upload_dir + filename
url_path_file = url_dir + filename
form.file.data.save(upload_dir + filename)
s = time.time()
print("向量化图片开始 %f" % s)
image = Image.open(file_path)
embedding = image_embedding(image, img_model)
d = time.time()
print("向量化图片结束 %f,耗时 %f" % (d, d - s))
# 写入图片到索引中
photo_id = random_lowerstring(32)
doc = {
"photo_id": photo_id,
"photo_url": url_path_file,
"photo_image_url": url_path_file,
"photo_description": "img desc",
"ai_description": "ai desc",
"photographer_first_name": "first_name",
"photographer_last_name": "last_name",
"photographer_username": "username",
"exif_camera_make": "exif_camera_make",
"exif_camera_model": "exif_camera_model",
"exif_iso": 100.0,
"image_embedding": embedding # 512个维度
}
print("插入图片photo_url:%s,photo_id:%s" % (url_path_file, photo_id))
resp = es.create(index=index_name, id=photo_id, document=doc)
print(resp)
return render_template('similar_image1.html', title='图片上传', form=form,
upload_ok='upload_ok',
original_file=url_path_file, model_up=True)
# 以文搜图
@app.route('/word4img_search', methods=['GET', 'POST'])
def word4img_search():
# 0.本地加载模型
# 1.获取文字,生成向量
# 2.knn搜索图片响应结果
index_name = INDEX_IM_EMBED
if not es.indices.exists(index=index_name):
return render_template('search.html', title='文字搜图', model_up=False,
index_name=index_name, missing_index=True)
form = SearchForm()
if request.method != 'POST':
return render_template('search.html', title='文字搜图', form=form, model_up=True, missing_index=False)
if not form.validate_on_submit():
return redirect(url_for('embeddings'))
# 生成向量 512维度
s = time.time()
print("向量化文字开始 %f" % s)
embeddings_arr = img_model.encode(form.searchbox.data)
d = time.time()
print("向量化文字结束 %f,耗时 %f" % (d, d - s))
search_response = knn_search_images(embeddings_arr)
return render_template('search.html', title='文字搜图', form=form,
search_results=search_response['hits']['hits'],
query=form.searchbox.data, model_up=True, missing_index=False)
唯一要注意查询和写入向量化数据时必须是同一个模型,这里模型为
clip-ViT-B-32
上下文搜索
使用模型为 sentence-transformers/msmarco-MiniLM-L-12-v3
- mapping
{
"les-miserable-embedded": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"line": {
"type": "long"
},
"ml": {
"properties": {
"inference": {
"properties": {
"is_truncated": {
"type": "boolean"
},
"model_id": {
"type": "keyword"
},
"predicted_value": {
"type": "dense_vector",
"dims": 384,
"index": true,
"similarity": "l2_norm"
}
}
}
}
},
"paragraph": {
"type": "text"
},
"timestamp": {
"type": "date"
}
}
}
}
}
- 改动的代码
@app.route('/text_search', methods=['GET', 'POST'])
def text_search():
index_name = INDEX_LES_MIS
if not es.indices.exists(index=index_name):
return render_template('embeddings.html', title='上下文搜索', model_up=False,
index_name=index_name, missing_index=True)
form = SearchForm()
if request.method != 'POST':
return render_template('embeddings.html', title='上下文搜索', form=form, model_up=True, missing_index=False)
if not form.validate_on_submit():
return redirect(url_for('text_search'))
s = time.time()
print("上下文向量开始 %f" % s)
text_embeddings = text_model.encode(form.searchbox.data)
d = time.time()
print("上下文向量结束 %f,耗时 %f, 向量长度:%d" % (d, d - s, len(text_embeddings)))
s = time.time()
print("上下文搜索开始 %f" % s)
search_response = knn_les_miserable_embeddings(text_embeddings)
d = time.time()
print("上下文搜索结束 %f,耗时 %f" % (d, d - s))
return render_template('embeddings.html', title='上下文搜索', form=form,
search_results=search_response['hits']['hits'],
query=form.searchbox.data, model_up=True, missing_index=False)
支持中文的大模型: 整理开源的中文大语言模型